Building Anagramatweest, a Twitter bot that finds and retweets anagrams
In this post, I share a small Node.js app I wrote to retweet anagrams to @anagrammatweest. Each pair of tweets is an anagram.
They’re also posted to Tumblr.
Note: I edited this post on 8/5/2017 to update screenshots to reflect cosmetic changes to the app since I first wrote this post. They’re immaterial except when noted explicitly.
Background
A little over a year ago, I wrote a small app in Scala to find anagrams in the Twitter firehose. That code is here, and I wrote a blog post about the process of finding a way to score anagram matches here. This was inspired by an existing twitter bot, anagramatron, that finds and retweets anagrams. I did this because I thought finding a good metric for scoring how interesting an anagram is (in other words, how likely you’d want to retweet it or share it with others) is an interesting problem, so I wanted to try it myself.
I had been running this app searching the firehose for anagrams on my personal computer for a few months and started to build a sizable database of tweets and anagrams. Some of my high-scoring anagrams were pretty funny, witty, poetic, or interesting, and that made me want to try to build my own bot like anagramatron so I could retweet the anagrams I was finding.
After getting annoyed with Scala implicits one night I ported the anagram finder to Java. The Java port is here. Interestingly, memory usage dropped significantly when moving from Scala to Java. I didn’t collect any data so this isn’t a rigorous observation but I think it typically used 250-350MB in Scala. In Java, it stays around 80-130MB. Memory usage drops over time, presumably once HotSpot has had time to think.
Building an anagram reviewer
Unfortunately, the majority of anagrams that my scoring methodology ranks highly are still not very interesting, meaning if I want to retweet them I need to manually review them. For example, “Pray then do” and “Phone dry at” is a real anagram I found that scores fairly high, with an interesting factor of 0.93 on a scale of 0 to 1. However, I don’t want to retweet those two tweets. They just don’t fit together at all. I need to be able to review anagrams before they can be retweeted so I can skip anagrams like that.
The author of anagramatron built an iOS app to review anagrams for this purpose. I wanted something similar that I could access either on my phone or in a browser, so I decided to build it as a web app that I could eventually host on a cheap Linux VPS. If the site is responsive enough it should be fine on either a desktop or mobile browser.
I initially explored going with Java since the anagram finder monitoring the firehose is written in Java. I looked into using JHipster, a yeoman generator for building modern Java web applications using Spring Boot and Angular, however I realized it’s overkill for something like this. The memory usage for a basic hello world JHipster app seemed to hang around 400-500MB. That’s a problem if I want to host this on a memory-constrained VPS. It’s also fairly heavyweight with tons of monitoring and logging features I don’t need.
After trying out some Node.js and Express tutorials I realized it was so easy to get started with Node.js that I almost had a working prototype just from tinkering around, so I decided to just go with writing the reviewer in Node.js.
UI for reviewing anagrams
One of the downsides to building this is that since I’m the only one currently using it I can’t really show it off on the internet, other than through a post like this and screenshots.
I review the anagrams in a table sorted by a combination of score and time, with buttons for actions to take for that anagram. The red X rejects, and I can either immediately approve each anagram or enqueue it to be retweeted and posted to Tumblr later. The arrows indicate in which order the tweets should be posted.
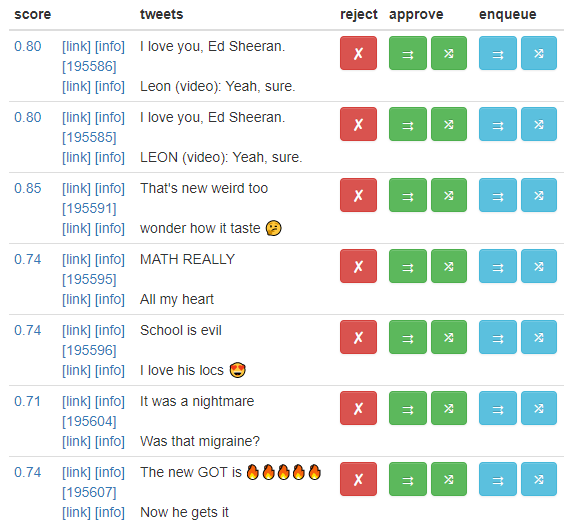
There are similar lists to unretweet and unreject matches that have been previously approved or rejected.
I use the node-schedule module to retweet anagrams on a schedule to space them out so that my retweets don’t overwhelm followers’ feeds. Here’s what that queue looks like, where I can also see if a queued match contains a tweet that I’ve already retweeted:
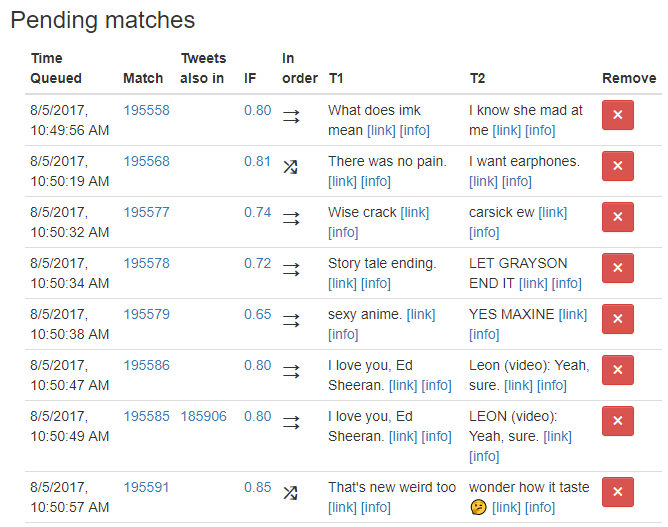
You can’t retweet a tweet twice, so if a match contains a tweet I’ve already retweeted, then I can’t retweet that match again; I can only post it to tumblr. If I retweeted the other match long enough ago, I’ll often unretweet it so that the queued match can be successfully retweeted.
In the above screenshot, I’ve enqueued two matches that both have the tweet “I love you, Ed Sheeran.”. That one tweet matched with two other tweets, “Leon (video): Yeah, sure.” and “LEON (video): Yeah, sure.”. Match 185906 contains “I love you, Ed Sheeran.” or “LEON (video): Yeah, sure.”. I know it contains “LEON (video): Yeah, sure.” since the previously queued match isn’t marked in the same way, which has “I love you, Ed Sheeran.”. Once 195586 is retweeted, both of the tweets in 195585 will have been retweeted, so it doesn’t make sense to unretweet the tweets in 185906.
The breakdown of the interesting factor score can be viewed in a modal pop-up by clicking on the score in the list:
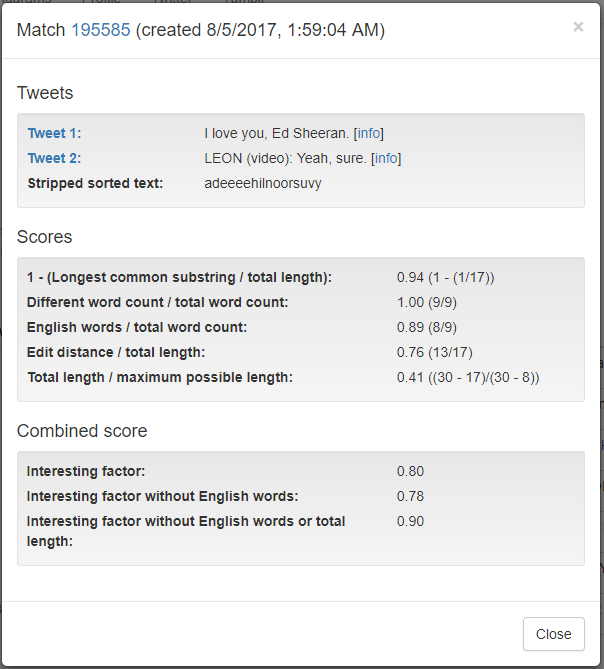
In the above screenshot the date of the match’s creation is 8/5/2017 even though this post is dated 12/30/2016. I updated some of the screenshots on 8/5/2017 to reflect changes I made shortly after 12/30/2016. However, this screenshot in particular reveals changes I’ve made to the scoring system after 12/30/2016. I describe the scoring system a little later in this post as of 12/30/2016, but since it would require extensive editing to update that section I’ve left that alone. If I write a new blog post on this topic I’ll describe the changes there. It’s already weird enough editing an old post months later, but it was bugging me that some of the screenshots I had in here no longer reflect what the UI looks like.
For fun I also have a page to show all the current N-way anagrams, where there are more than two tweets that form an anagram. This tends to happen quite a bit with variants on common phrases like “good morning” or “happy new year”. For example, I have six tweets for the stripped sorted text “aabdhiimrsttyyyyyyy”:
- ITS MA BIRTHDAYYYYYYY
- it’s my birthday ayyyyy 😛
- IT’S MY BIRTHDAYYYY YAY 💝👑🎉
- Ayyyyy it’s my birthday
- Yayyyy it’s my birthday 🎁🎈🎉
- ITS MY BIRTHDAAYYYYYY 🎉🎉🎉🎉🎉🎉🎉
As a side note, I most likely definitely have encountered more than just six tweets with the above set of letters. However, in order for me to record the tweet it can’t be a duplicate of an existing tweet I already have recorded, and in order for it to be an anagram each of those six tweets must be significantly different enough from at least one of the other tweets for it to reach my score threshold and create an anagram match for it.
UI for anagram statistics
I also built out a pretty extensive statistics page to get insight into the anagrams I’m creating and reviewing. There are quite a few tables, but each table has a chart which is more interesting to look at so for brevity I’ll only show the screenshots.
The following chart shows the number of retweets and tumblr posts I’ve made in the past few days, and the average interesting factor of the retweets and tumblr posts for that day.
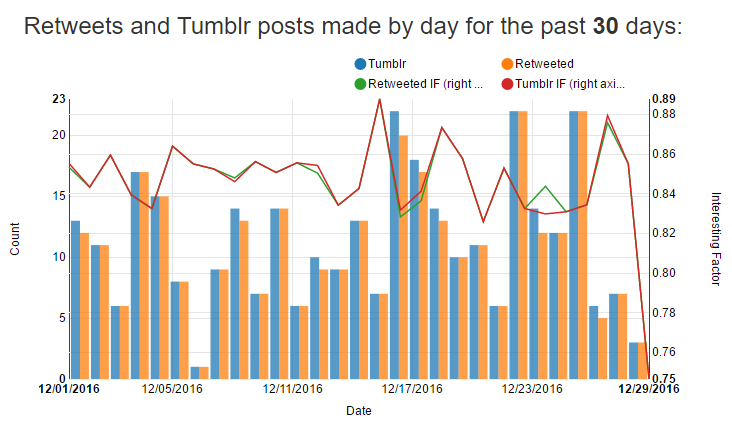
The number of retweets and tumblr posts can differ since some anagrams contain tweets that I’ve already retweeted as part of other anagrams. Since you can’t retweet the same tweet twice, I skip retweeting that anagram and post it only to Tumblr.
All of these charts are built using nvd3.js.
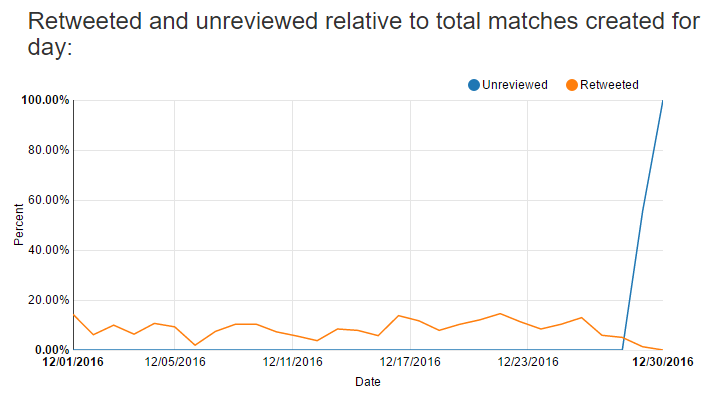
The following chart shows the percentage of unreviewed and retweeted anagrams for all anagram matches created on that day. I can see for the past two days I haven’t been reviewing any tweets and have a backlog to get to. I approved or rejected everything before that for the month of December. The retweeted percentage can start to give you an idea of how few anagrams I approve.
The following chart shows the raw numbers for actions taken for each day. It’s easier to look at as a stacked bar chart, but unfortunately the stacks are totals so the total height of the bar is meaningless and slightly misleading.
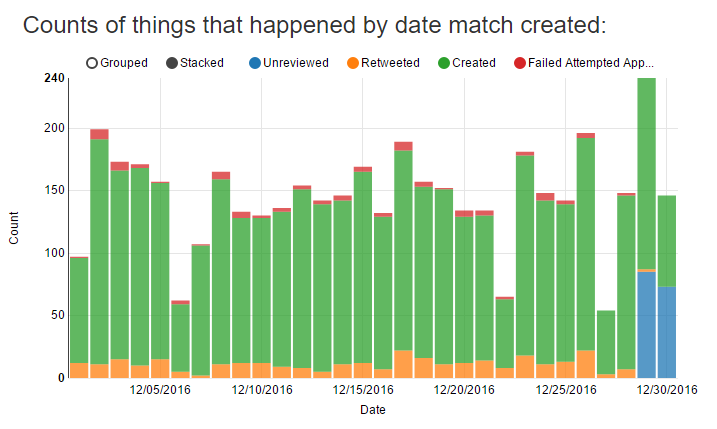
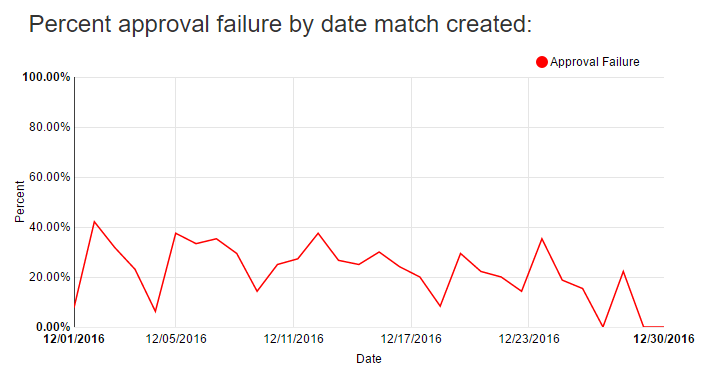
Failed attempted approvals are when I try to retweet an anagram, but one or both of the tweets no longer exists. This can happen if someone tweets, I see it in the firehose, but then before I have a chance to retweet it, the user deletes the tweet or takes their account private. This phenomenon led me to build a scheduled job that every minute makes calls to Twitter to check for the continued existence of tweets in my database.
The following chart shows just how often this happens:
The following charts shows the average interesting factor for actions taken for anagrams created on a given day:
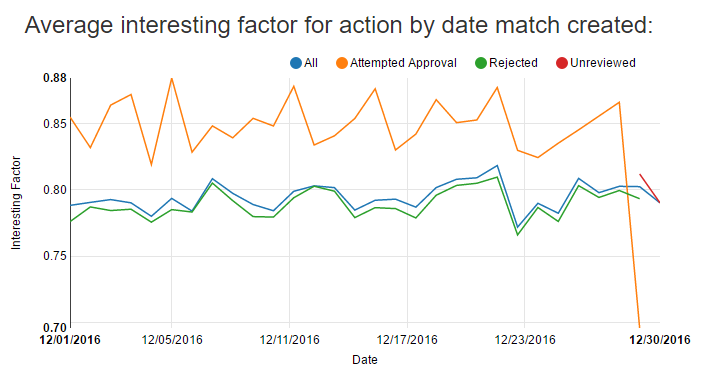
The attempted approval drops on 12/29 since I only tried to approve one or two low scoring anagrams that day, leading to a skewed average. On average, the anagrams I attempt to approve score higher than all anagrams, and the rejected anagrams tend to score slightly below the average for all created anagrams.
The following chart shows the percentage of anagrams for each interesting factor score that I have retweeted or have left to review. I still have quite a few legacy matches between 0.40 and 0.60 from before I increased my threshold to 0.60. They’re likely all terrible. As the interesting factor increases, I tend to approve a greater percentage of the anagrams at that score bucket.
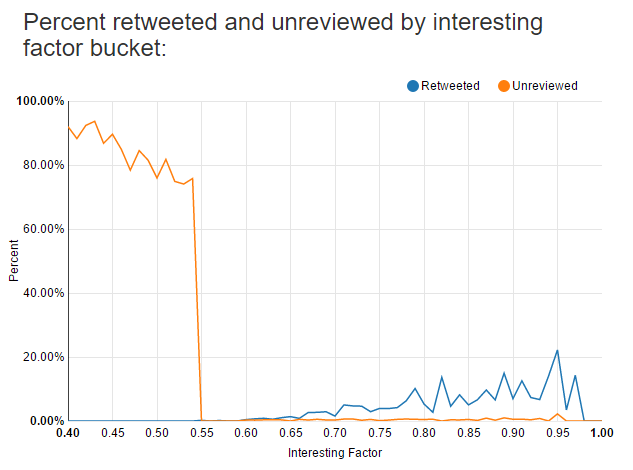
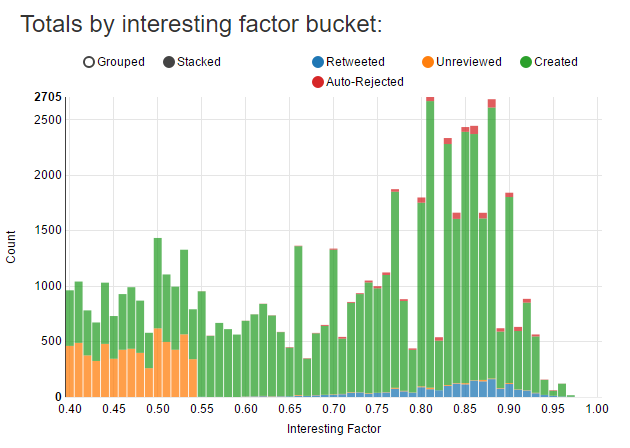
The following chart shows the raw numbers for the above chart. Auto-rejected anagrams are anagrams I attempted to approve but because one of them no longer exists or is visible, it’s marked as rejected.
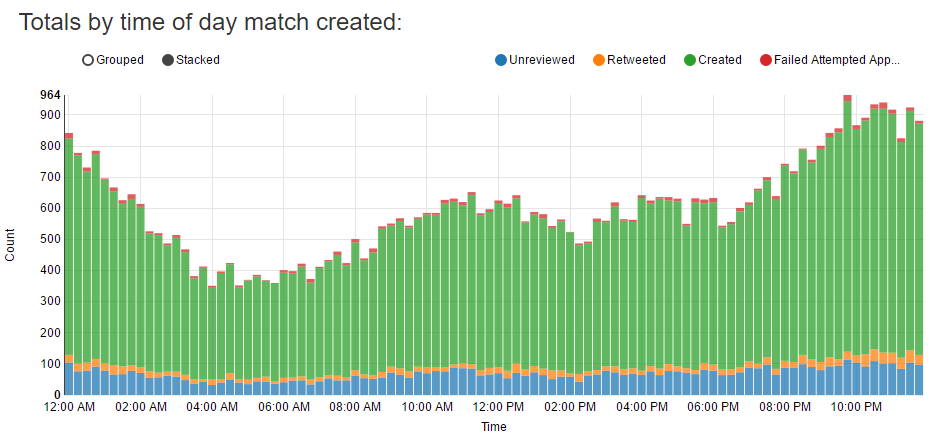
When grouping anagrams by the time of day they’re created I can see I tend to find more anagrams late at night. One reason for this could be that people tend to tweet more at night, however this data can’t really be trusted since I haven’t been running the anagram finder consistently or for the full day on days I’ve been running it.
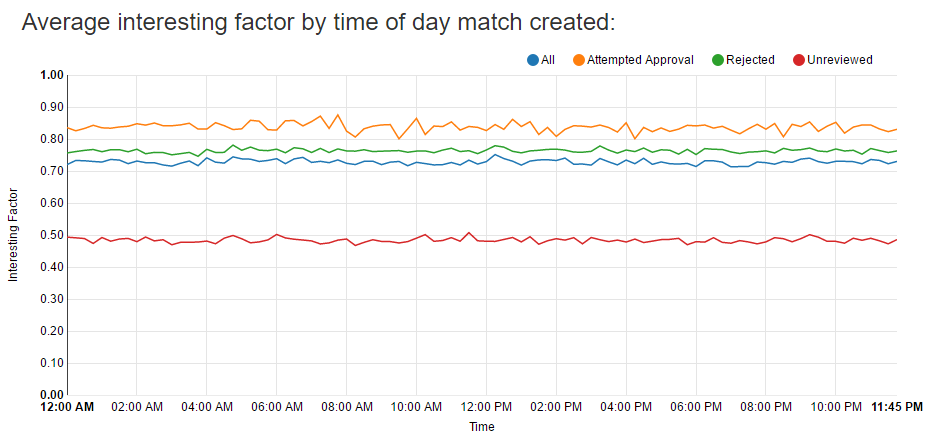
The following chart shows the average interesting factor for matches created at different times of day. This was fun to explore, but the conclusion is that the time of day doesn’t seem to affect the scores of matches I approve or reject.
Nodemon
Nodemon is amazing. Once I got it set up I could make a change, refresh, and immediately see my changes. This enables a very tight feedback loop during development, where you can make small changes incrementally and see your progress without needing to recompile or manually restart the web server. It’s pretty incredible how quickly Node.js and express start up.
I believe a tool like this is especially necessary with a dynamically typed language like JavaScript. Most errors I encountered during development were typos on property names that just simply wouldn’t have happened in a statically typed language.
Promises
Promises are a pain. They’re worlds better than dealing with many nested callbacks, but it’s still a pain to deal with control flow and error handling when making many asynchronous calls. It really makes me appreciate the work the C# team did with async/await to make asynchronous code visually comparable to synchronous code. I look forward to when async/await is prevalent in the JavaScript world. While working on this project I fervently checked Node.js v7’s status to check if they were going to incorporate V8 5.5 (with stable async/await support) into Node.js v7 so I could start using it. Looks like it’s coming in Node.js v8.
Changes to scoring methodology
When I first started searching for anagrams I accepted interesting factor scores as low of 0.40. There are a few gems between 0.40 and 0.60, but they’re mostly terrible and not worth the time to check. I’ve moved my minimum up to 0.60, so I now only create anagrams to review if they’re between 0.60 and 1.0.
I also reduced the maximum length of tweets I consider to 30 characters. At one point, I had 27 million tweets collected but only a handful of anagrams with more than 30 characters. After deleting those long tweets, I went from 27 million tweets to 9 million, and my database shrunk from 8 GB to ~1.5GB. There are undoubtedly awesome anagrams that are more than 30 characters long. However, the amount of disk space it takes to find them isn’t worth it.
Observations on how the match scoring methodology is working out
My composite score for anagrams, something I’ve been calling the “interesting factor”, is an averaged score of three other scores:
- Longest common substring ratio: the ratio of the longest common substring between the two tweets relative to the length of the tweets.
- Word count ratio: the ratio of the number of different words to the number of total words between the two tweets.
- Edit distance ratio: the ratio of the edit distance (specifically Damerau–Levenshtein) between the two tweets relative to the length of the tweets.
Each of the above scores are weighted equally.
Comparing scores for all approved and rejected anagrams
After approving and rejecting anagrams for a while I can now calculate the relative importance of each of these three scores. The following table shows the average score for all rejected anagrams subtracted from the respective average score for all approved anagrams, for anagrams that have an interesting factor above 0.60.
| Interesting factor | Longest common substring ratio | Word count difference ratio | Edit distance ratio |
|---|---|---|---|
| 0.044 | 0.074 | 0.020 | 0.039 |
On first glance I’m impressed that the interesting factor number is so low. Do all of my approved anagrams really only have an average interesting factor of 0.044 greater than all of my rejected anagrams? My gut reaction is that this must be a terrible way to score anagrams if in the domain of 0.60 to 1.0 my approved anagrams are only 0.044 higher than my rejected anagrams. However, I need to remember my rejected anagrams also meet the same filters that the eventually approved anagrams do. That is, I’m not comparing the average score of approved anagrams to the set of all possible anagrams I could find. The difference would be more stark in that comparison.
The average longest common substring ratio also seems to be much higher than the other two ratios in the anagrams I approve. I’m not sure if I’ve approved enough anagrams yet for this difference to be statistically significant. I’m afraid to conclude that this means I should weight the longest common substring ratio higher in the combined interesting factor score. It’s still possible that the contribution of the other two scores helps to bring in additional interesting anagrams that score poorly based on the longest common substring ratio, or that there’s some additional non-obvious benefit from bringing in the other ratios. After running a few ad-hoc queries this isn’t clear. I’ll have to investigate this more.
Comparing scores by each interesting factor bucket
There’s more detail when looking at the averages for each interesting factor score bucket, where each bucket is the interesting factor truncated to the nearest hundredth (e.g. 0.83 where 0.83 <= interesting factor < 0.84).
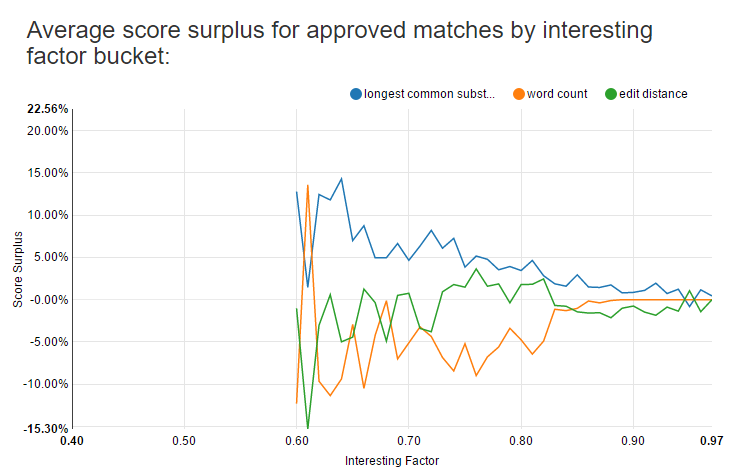
For high scoring anagrams above 0.83 it looks like none of the three measures has an outsized contribution. Between 0.73 and 0.83 it looks like the longest common substring ratio and edit distance ratio tend to contribute more than the word count ratio, and below 0.73 the longest common substring ratio is much higher than the other two. However, this data is pretty noisy since as the scores decrease there are fewer and fewer approved anagrams relative to the number of rejected anagrams.
The above chart shows scores down to 0.40 since I still have some legacy anagrams below 0.60 that I haven’t reviewed yet.
Ideas for improving anagram match scoring
After working on this I’ve thought of a few ways I could improve my current anagram scoring criteria.
I could reweight the anagram scores based on their relative importance. For example, give the longest common substring ratio a greater weight than the word count difference ratio or edit distance ratio. Currently, they’re equally weighted since the three of them are simply averaged together to form the interesting factor. However, this would require quite a bit of experimentation and would at best be an incremental improvement. It would be a big time investment for little maximum possible return.
I could add an additional score metric based on the presence of English words in each of the two tweets in the anagram. I’ve found the anagrams I tend to approve tend to have actual English words in them. To implement this I could use a dictionary to create a score based on how many words in the tweet exist in the dictionary. Loading all English words into a hashset or trie would be easy and provide very fast lookups, but could possibly result in high memory usage depending on the size of the dictionary. I’ll have to experiment to see how much that’s actually the case, and maybe explore solutions involving fast lookups from an on-disk dictionary.
I could create a score based on the length of the tweets in found anagrams. I’ve found that longer anagrams tend to be more interesting. Unfortunately, there are far fewer anagrams for long tweets than there are for shorter ones, and ranking highly long anagrams is at odds with my restriction to less than 30 characters for space concerns. The sweet spot might have to be 20 to 30 characters in the trade-off between space and quality.
I could create a supervised machine learning model to score whether an anagram should be approved or rejected. Now that I’ve been approving and rejecting anagrams for a while, I have a labeled data set categorizing anagrams into the two classes of approved and rejected. A machine learning model might be able to learn patterns in the labeled tweets. However, I’ve only reviewed a few thousand anagrams, which might not be sufficient to do this yet. If I use an online algorithm maybe I could continuously retrain it as more anagrams are reviewed.
Anagrammatweest
I retweet anagrams to @anagrammatweest. The name is intended to be a portmanteau of Twitter anagrammatist.
I initially only wanted to retweet them, however after I started reviewing and retweeting anagrams I found that over time many tweets are no longer visible even after I retweet them.
They can disappear because:
- The tweet is deleted.
- The user takes their account private.
- The user’s account is banned.
- The user blocks me.
All of the above situations take the tweet off of anagrammatweest’s timeline, meaning I’ll then have a broken anagram pair on the timeline. This is very confusing for anyone scrolling through the anagram timeline since they’ll be expecting every two tweets to be an anagram, but every so often they’ll find one tweet that doesn’t anagram with any of the surrounding tweets.
To fix this I initially tried using the Twitter API to periodically check my retweets to see if any of the underlying tweets are no longer visible to me, and delete any of these broken pairs. This only easily works for the past 3,200 tweets due to Twitter API limits. I used this for a while, but it’s too much work to maintain and test so I stopped doing it and decided instead to follow anagramatron’s lead and also post anagrams to Tumblr. There, if the tweet is no longer visible, at least the original text will still be present in each Tumblr post.
Each anagram I retweet is posted to Tumblr here.
Totals so far
I haven’t been running the anagram finder consistently since I started doing this in 11/2015, and I’ve tweaked the score threshold to limit the number of anagrams I create a few times. The following chart can give you an idea of how many anagrams I’ve found over time since I started searching for them:
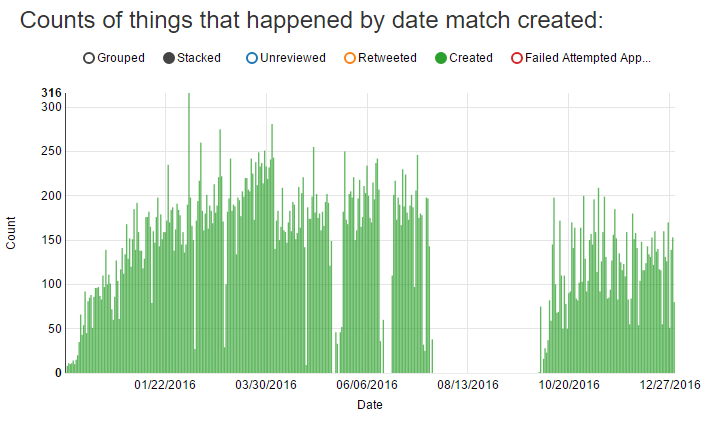
I didn’t bother running this over the summer and only picked up interest in it again in the fall.
As of 12/30/2016 I’ve found 48,492 matches in 10,175,959 tweets.
37,249 of these have an interesting factor above 0.60. I’ve retweeted and/or posted to tumblr about 1,860 anagrams.
Code
The code for the anagram reviewer written in Node.js can be found here.
The initial Scala anagram finder is here. It’s outdated and no longer maintained. If you want to look at code, I recommend looking at the one written in Java.
The Java port which I currently use and maintain is here.
Follow me!
If you’ve made it to the end of this post, you should follow @anagrammatweest!