Finding anagrams on Twitter
A while ago I stumbled across anagramatron, a Twitter bot that finds anagrams from a sample of the Twitter firehose and retweets them. I read in the description of the project that anagrams are manually curated.
I found the concept of finding anagrams on Twitter fascinating, and thought there must be a better way to find interesting anagrams than manually sifting through matches to find interesting anagrams. If one could score matched tweets based on how interesting the match is, matches could be filtered or sorted to only the most interesting ones, making the task of finding them much easier.
I thought one possible way to score anagram matches would be to calculate the edit distance between the two tweets. I reasoned that two matched tweets with a low edit distance wouldn’t be very different from each other and thus probably not a very interesting anagram, while two matched tweets with a high edit distance would be very different from each other and likely very interesting.
I thought of edit distance because I have previously had great success using it at my day job when implementing fuzzy-search algorithms for Medicaid data. For example, to find social security numbers with transposed numbers due to data entry errors, or misspelled names and addresses.
I’ve been learning Scala on my own recently so I thought I’d actually try to implement this as an exercise in Scala just to see what kind of results I could get.
Getting tweets to score
I use Twitter4j to get a streaming sample of tweets. The basic stream sample available through the Twitter API exposes a very small sample of the total Twitter firehose – somewhere in the vicinity of a fraction of 1%. I save candidate tweets and anagram matches in an H2 database using Slick.
I mostly wanted to explore the data to find a good way to score and rank interesting anagram matches, so I didn’t aggressively filter out uninteresting matches. If I turn this into a bot of my own like anagramatron I’d eventually want more filtering, but for now I’m fine generating matches for tweets that are actually complete duplicates (e.g. multiple tweets like “I can’t sleep”).
Even though I don’t filter the matches, I do perform some basic filtering of the tweet stream. For example:
- English tweets
- No retweets
- No URLs
- No hashtags
- No @replies or @mentions
- > 8 alphanumeric characters
The remaining tweets after the above filters are mostly just plain text.
If tweets meet the above filters, I save the original tweet text, its lowercase alphanumeric text (which in the code I’ve been calling “stripped” since I strip out everything that isn’t a character from ‘a’ to ‘z’ or number from 0 to 9), and the sorted alphanumeric text. For example, both “not a smoothie” and “NOT A SMOOTHIE!!!!!” would become “notasmoothie” when stripped. Sorted, it becomes “aehimnooostt”.
By storing the sorted text finding matches is very easy. For each incoming tweet from the stream, I can find if it matches any saved tweet by sorting the incoming tweet’s alphanumeric text and querying all saved tweets’ sorted alphanumeric text. If there are any matches, those tweets are anagrams. For example, “his one tomato” and “not a smoothie” when sorted are both “aehimnooostt”. When I receive “his one tomato”, I sort the text to get “aehimnooostt”, and then query all my saved tweets for this sorted text to find the previously saved tweet “not a smoothie” that also has this sorted text.
When sampling English tweets I receive about 15 to 20 a second depending on the time of day. After filtering, I end up storing about 2 tweets a second. After collecting tweets and matches for a few days, I saved 665,320 tweets and 81,913 matches. I didn’t record the total number of incoming tweets, but if I captured 2 tweets for an average of 17.5 per second, then I received an estimated 5,821,550 total tweets. The H2 database is currently 260MB.
Many of the matched tweets are complete duplicates except for small changes in capitalization, punctuation, or extra non-alphanumeric characters such as emoji or emoticons that don’t affect a tweet’s eligibility to be an anagram. I can find these by searching for matches where the alphanumeric text for each tweet is exactly the same. For example:
| Tweet 1 | Tweet 2 |
|---|---|
| love yourself | Love yourself |
| Good night. | good night |
| I’m ready to go home | I’m ready to go home 😴 |
| I’m so hungry :( | I’m so hungry 😩😩😩😩 |
| Today is not my day😅 | today is not my day |
| my stomach hurt☹ | my stomach hurt 😩 |
| Good morning! 😁 | Goodmorning |
| wait for me to come home | Wait for me to come home 😭😭😭😭😭😭😭😭 |
| Can’t wait for this semester to be over 😓 | Can’t wait for this semester to be over 😴 😴 ✌ . |
| I want sushi 🍙 | I want sushi ): |
There are many duplicate tweets involving song lyrics, names of song tracks, and artist names. There are quite a few people out there tweeting variations of “Justin Bieber - Love yourself”.
There are also quite a few bots posting the text “Get Weather Updates from The Weather Channel.” followed by the current time. Here’s a sample of some of these accounts so you can see for yourself:
- https://twitter.com/stwb29451
- https://twitter.com/03832trdb
- https://twitter.com/stwd29610
- https://twitter.com/02670gnlc/
I saw 1,667 accounts posting this kind of tweet. Matches from these tweets currently comprise 50,736 of my 81,913 matches.
The weather update tweets and exact matches like in the table above comprise 80,882 of my 81,913 matches, leaving only 1,031 matches remaining. That leaves 1,031 matches for possibly interesting anagrams.
Trying Demerau–Levenshtein Distance
I calculated the edit distance of the alphanumeric, or stripped, text for each match found. Here’s a sample:
| Edit Distance | Tweet 1 | Tweet 2 |
|---|---|---|
| 21 | Justin beiber | I’ll show you | ill show you // justin bieber 🎧 |
| 21 | She don’t wanna be saved don’t save her | Don’t save her, she don’t wanna be saved 🙅 |
| 21 | Taylor swift // wildest dream | ▶Wildest dream - Taylor Swift 🎧 |
| 20 | If all the world’s a stage, I want to operate the trap door. ― Paul Beatty | Paul Beatty~ If all the worlds a stage I want to operate the trap door. |
| 20 | One last time // ariana grande 🎶 | Ariana Grande // One Last Time |
Disappointingly, these are pretty similar – the words are just rearranged. The edit distance is high, but only because it takes many edits to rearrange the words.
Just taking the raw distance also introduces a bias towards long tweets. I need to normalize it against the length of the stripped alphanumeric text to try to eliminate this. Changing it to a ratio definitely ranks shorter tweets higher, but they’re mostly still just the same words swapped around; here are some of the most highly ranked matches using the ratio of edit distance to the length of the string:
| Edit Distance Ratio | Tweet 1 | Tweet 2 |
|---|---|---|
| 1 | fresh start 😁 | Start fresh ✨ |
| 1 | Friend please. | Please friend😂 |
| 1 | loft music // the Weeknd 😍 | The Weeknd | Loft Music 💫 |
| 1 | Trap Phone ….. | Another PP |
| 1 | Dinner for breakfast | Breakfast for dinner😋 |
| 1 | Weekend finally!! :) | Finally weekend😎 |
There’s a non-junk anagram in there! It’s not at all interesting, but “Trap Phone …..” and “Another PP” are not at all alike. I’m starting to make progress, but am still inundated with uninteresting matches.
Since I’m comparing strings of equal length I also at one point tried Hamming Distance between matched tweets. However it seems to act as an upper bound to Demerau–Levenshtein distance so the results weren’t significantly different. However, it is far simpler to implement. It’s a one line method in Scala:
def hammingDistance(s1: String, s2: String): Int = {
s1.zip(s2).count(c => c._1 != c._2)
} If I ever found the Demerau–Levenshtein distance calculation to be a performance problem I might switch to using Hamming distance. However, it’s not too expensive for strings this small, and since I don’t need to calculate the distance very often I doubt this will ever be a concern.
Trying Word Count Difference
Many of the uninteresting matches in the above table seem to have the exact same words in them. I thought maybe I could penalize these matches by counting the number of words that are different between the two tweets. Like Demerau–Levenshtein distance this raw value introduces a bias, this time for tweets with a lot of words. If I divide it by the total number of words between the two tweets I can get a score from 0 to 1 representing how different the sets of words are.
Alone, I can see it’s not very useful and is very sensitive to how I tokenize the tweet into words since it thinks matches like “goodnight” and “good night” are three words total:
(“WC Ratio” stands for word count ratio.)
| WC Ratio | Tweet 1 | Tweet 2 |
|---|---|---|
| 1 | Good Morning 🌅❤️ | Goodmorning |
| 1 | Good morning! 😁 | Goodmorning |
| 1 | Goodnight 😘😄 | good night |
| 1 | Goodnight 😊😴 | good night |
| 1 | Good afternoon ⛅ | Goodafternoon 🌞 |
| 1 | goodnight | good night |
However, if I average it with the edit distance ratio I start to get really promising results:
(“E + WC Ratio” stands for the averaged edit distance and word count ratio)
| E + WC Ratio | Tweet 1 | Tweet 2 |
|---|---|---|
| 1 | Trap Phone ….. | Another PP |
| 0.958 | Am I too honest? ☺️ | 🍄🧀💉👶 = not a smoothie |
| 0.954 | Heartbroken 😞💔 | broken heart |
| 0.954 | heartbroken | broken heart |
| 0.949 | i’m so hot wtf | Who tf is Tom? |
| 0.944 | Hungriest. | Sure thing 😏 |
| 0.944 | Me is happy | Happyisme |
| 0.909 | The Game is ON | Omg he’s eatin!!! |
| 0.900 | Studio time 😏 | I’m used to it |
Lots of interesting anagrams! I see the one anagram from the previous table is now scored most highly, and lots of others have bubbled up. However, I still see the negative effect of the word count ratio with the highly scored “heartbroken”/”broken heart” pairs.
Trying Longest Common Substring Distance
I read about longest common subsequence (or substring) distance on the Wikipedia page for edit distance and thought maybe it could overcome the problems with the word count difference. None of the anagrams in the above table, outside of the two “broken heart” matches, have very long substrings in common with each other. However, the “broken heart” matches do; “broken” is a pretty long substring common to both of them. I could use this high common substring length to weigh down this match that otherwise ranks high due to a very high edit distance ratio and word count difference ratio.
Since the length of the longest common substring is very high when the tweets are similar, I can’t divide this by the total length to come up with a ratio that is high when the tweets are most dissimilar, so I need to subtract it from 1 and use its inverse ratio.
After implementing it, I can see these kinds of matches drop off. Averaged together, I call these ratios – the edit distance ratio, the word count difference ratio, and the inverse longest common substring distance ratio – the Interesting Factor. When the Interesting Factor is high, chances are the tweet is interesting.
| E Ratio | WC Ratio | LCS Ratio | Interesting Factor | Tweet 1 | Tweet 2 |
|---|---|---|---|---|---|
| 1 | 1 | 0.777 | 0.925 | Trap Phone ….. | Another PP |
| 0.916 | 1 | 0.833 | 0.916 | Am I too honest? ☺️ | 🍄🧀💉👶 = not a smoothie |
| 0.888 | 1 | 0.777 | 0.888 | Hungriest. | Sure thing 😏 |
| 0.818 | 1 | 0.818 | 0.878 | The Game is ON | Omg he’s eatin!!! |
| 0.800 | 1 | 0.800 | 0.866 | Studio time 😏 | I’m used to it |
| 0.899 | 1 | 0.699 | 0.866 | i’m so hot wtf | Who tf is Tom? |
| 0.789 | 1 | 0.789 | 0.859 | Ouch!!! This | cold weather! |
| 0.777 | 1 | 0.777 | 0.851 | gas or whet | Who’s great |
| 1 | 0.714 | 0.833 | 0.849 | Please don’t go …. | And go to sleep |
| 0.800 | 1 | 0.699 | 0.833 | bingo night 👀 | nothing big |
Matches with an Interesting Factor above 0.80 tend to be pretty interesting. There are some poor matches between 0.70 and 0.80 but still some interesting anagrams. Below 0.70 the results are mostly bad, though there are still a few gems. It’s rare to find matches below 0.50. However, good matches below 0.50 do exist… they’re typically not very interesting, but they still exist.
Trying Intersection of Word Permutations
The longest common substring distance works great when the words are in the same order, for example when examining the match “broken heart” and “brokenheart”. Except for the space, all of the characters in those two strings are in the same order. In this example the longest common substring distance is the length of the alphanumeric text. However, when the words have a different order, such as “heartbroken” instead of “brokenheart”, the longest common substring distance is not as useful since now “broken” is the longest common substring. Many of the poor matches with an Interesting Factor of 0.60 or higher seem to be cases like this. For example:
| IF | Tweet 1 | Tweet 2 |
|---|---|---|
| 0.787 | heartbroken | broken heart |
| 0.777 | Me is happy | Happyisme |
| 0.696 | morning good | Goodmorning |
| 0.692 | iloveyou,Goodnight💤 | Goodnight, I love you |
| 0.683 | good morning good night | GoodNight❤/GoodMorning🍃 |
I realized I could completely detect these cases by calculating all possible permutations of the words in both tweets and testing to see if the permutations overlap. Unfortunately, calculating the permutation of all possible words in a tweet can become very expensive if the tweet has a lot of words. I tried implementing this and quickly maxed out my CPU along with rapidly ascending memory usage. It got stuck on this tweet:
let's be honest with ourselves: did we really come this far to just watch it go down the drain?
I’ll leave it as an exercise to the reader to figure out how many permutations of words there are in that string.
After limiting it to only perform this calculation if the tweet has 6 or fewer words, it works great; I’m now able to completely exclude results like in the above table. I get good matches down to an Interesting Factor of 0.60 now.
Adding it all up
Sorting matches by Interesting Factor provides a good way to order matches, but it’s not a good way to limit the set of anagrams to review. I could filter out matches with an Interesting Factor less than 0.40 or 0.60, but this would exclude possible diamonds in the rough below whatever threshold I set.
After playing around with the queries for a bit, I found that I can seem to include all interesting anagrams in a reasonably sized result if I simply query for matches where all of the three ratios I described above are greater than 0, along with the rule for excluding rearrangements of words (at least when both tweets are 6 words or less). This limits the matches to 313. 62 have an Interesting Factor of 0.60 or higher. After searching all other matches outside of those 313 I can’t seem to find anything close to resembling an interesting match. After some additional filtering of matches to stop some types of duplicate matches, it looks like 313 would shrink to about 200. Reviewing 200 matches a week doesn’t sound too bad.
High Memory Usage - H2?
After running this on my desktop computer for a few days I noticed the CPU and memory usage started to climb. It was using a steady 35% of my i5 3570K over-clocked to 4.2GHz and almost 2GB of memory. This is higher than I expected.
I created a heap dump using jmap and then examined it with jvisualvm. Here’s a list of the classes using the most memory sorted by size:
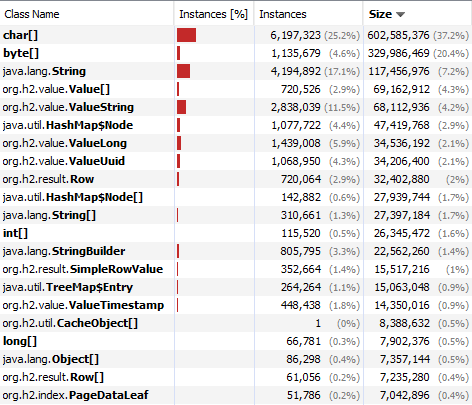
Wow! Over 1GB for char[], byte[], and String alone! After browsing the contents of some of the instances for a bit I’m pretty sure most of this is from H2.
After digging through the logs for a bit I realized that the query to find tweets with the same sorted alphanumeric text was taking longer and longer as the size of the database increased. I was now trying to execute a query about every 500ms that took 1200 ms. Since Slick’s API is asynchronous and non-blocking it’s very easy to bombard the database with queries that it can’t keep up with.
After adding an index on that column queries went from 1200 ms to <20 ms and the problem disappeared. CPU usage is now <1% and memory usage hangs around 300MB.
Oops. I should’ve realized earlier that would become a problem. It feels great to make one small change and have a query perform over 60 times faster though.
What’s Next?
Better Filtering
I need to start filtering out matches if they don’t score high enough. This will drastically shrink the number of matches found, mostly by eliminating duplicate matches.
I should probably also exclude tweets with numbers. There don’t seem to be any interesting matches with numbers yet, and although I can imagine some exist, excluding tweets with numbers would also filter out a lot of garbage tweets like the weather update tweets that make up most of my current matches. However, maybe I can keep numbers but just have an explicit filter for the weather tweets. I’ll have to experiment with this.
I also need a better way of handling multiple matches for the same tweet. Currently, when querying for a matching tweet, I only match to the first one I find if it exists. For example, I might get “not a smoothie” and “hot as emotion” one day and pair them as a match. The next day I might receive “shoe at motion” which is a pretty interesting anagram to both of the previous two tweets. Currently, I would pair “shoe at motion” with the first tweet I find, which could be “not a smoothie”. It wouldn’t be paired with “hot as emotion”, even though that would qualify as a match too – and an interesting one at that. In other words, I currently don’t handle very well the possibility for an interesting 3-way anagram.
If I create pairs for all interesting matches, I could possibly run into an explosion of matches for a given sorted alphanumeric string. For example, if I received five anagrammatic tweets it could result in up to 10 combinations of interesting matches. However, since I’m using a relational database I can easily group by the anagram group’s sorted alphanumeric text to detect these matches if I wanted to perform some action on them collectively. The probability of finding more than one interesting anagram match for a given sorted alphanumeric string in a reasonable timeframe seems low however.
Change Database
I may try switching to PostgreSQL. I have some other ideas for bots and if they share the same database then I need one that can handle multiple processes. H2 does have a server mode, but Postgres is probably more suited to this purpose and I believe has better performance anyway.
Microservices
If I’m going to explore implementing other Twitter bot ideas I may need to explore breaking things up into microservices. I should only have one connection to Twitter receiving tweets, and if I don’t break things up then I’ll have multiple bots running in one monolithic Scala app consuming that one tweet stream. This might be easy to deploy and would probably perform well, but would become a hassle when trying not to affect the operation of other functions. For example, if I need to redeploy the monolithic app to add some new bot functionality, then I can’t process tweets for the anagram bot while I do that. If I instead break things up into distinct services, I can have one app whose sole job is to stream tweets to a message queue; other bots or functions can exist as completely separate services that independently pull items off the queue. I’ll have to look into this a little more.
A note about anagramatron’s filtering
I mentioned earlier that the motivation for me doing this was to find a better way to find anagrams on Twitter than manually sifting through matches to find interesting results. I thought this, and started working on my own approach in Scala, without even looking in-depth at anagramatron’s source code.
This was dumb.
It didn’t even occur to me to look at anagramatron’s source since I really just wanted to try this all out myself. However, once I was nearly done coming up with a way to score anagrams on my own it occurred to me to actually look deeper into anagramatron’s source. It is not completely manually curated; there’s quite a bit of intelligent filtering going on in there. I now feel a little silly for believing this wasn’t the case.
There’s even an issue on the project for introducing Demerau–Levenshtein distance. I didn’t see it before I started, but this is where I got the idea to try Hamming Distance.
Code
The code I wrote when writing this post can be found in this repository.